re_graph.pl - Graph regular expression
re_graph.pl [-d] [-o out_file] [-x min-x] [-y min-y] regular-expression [string]
The re_graph.pl program graphs regular expressions. The guts of the regular expression engine is a simple state machine. The various states and operations in the regular expression parser can be displayed using a surprisingly simple diagram.
A few notes on what you are looking at:
The nodes Start and Stop denote the beginning and end of the regular expression.
The solid squares denote atoms. Lines indicate the next state. When a line splits, the state machine will take the top line first. If it's path is blocked it will backup and take the next lower line. This is repeated until it finds a path to the end or all paths are exhausted.
Brown boxes indicate a grouping operation, i.e. ().
Green boxes indicate a zero with test. The state machine will perform the test inside the box before moving ahead.
For more information, see the tutorial below.
If the system is used in graph / execution mode, a series of files will be written using the printf style file name specified.
This tutorial shows what happens when a set of sample regular expressions are graphed. This set of regular expressions closely follows the Chapter 4 of ``Perl for C Programmers'' by Steve Oualline.
The set of regular expressions used for this tutorial is:
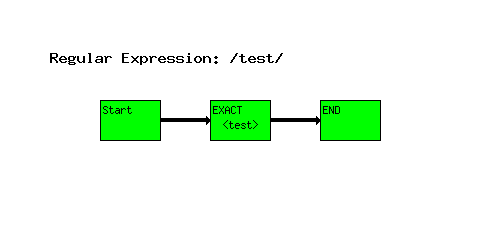
test
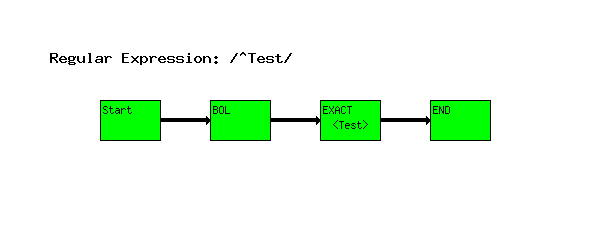
^Test
^ *#
^[ \t]*#
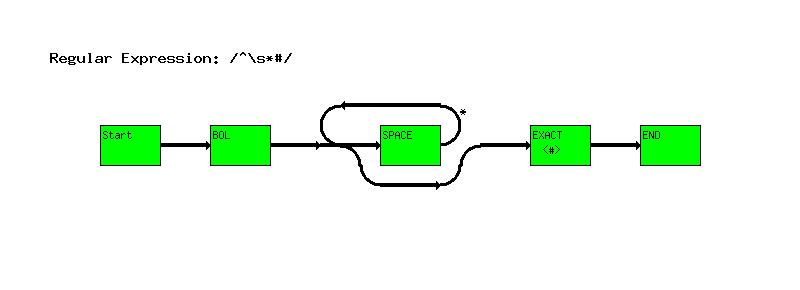
^\s*#
([^#]*)(#.*)
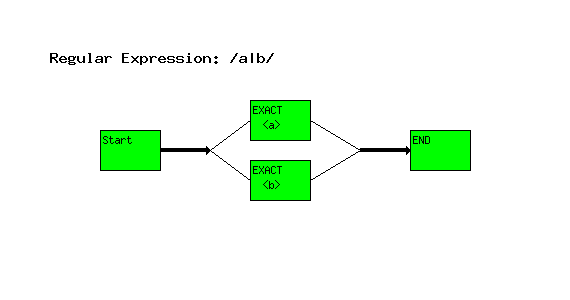
a|b
^(([^#"]*|".*")*)(#.*)
^((?:[^#"]*|".*?")*)(#.*)
^((?:[^#"]*|".*?(?<!\\)")*)(#.*)
Let's take a look at the graphs produced by these expressions.
The ``Start'' node indicates the start of the regular expression.
The ``EXACT <test>'' node tells the engine that the text must match the text ``test'' exactly.
The ``END'' node indicates the end of the regular expression. If you reach the ``END'' node, a successful match was found.
Flow is a straight line from ``Start'', through the ``EXACT'' check, to end.
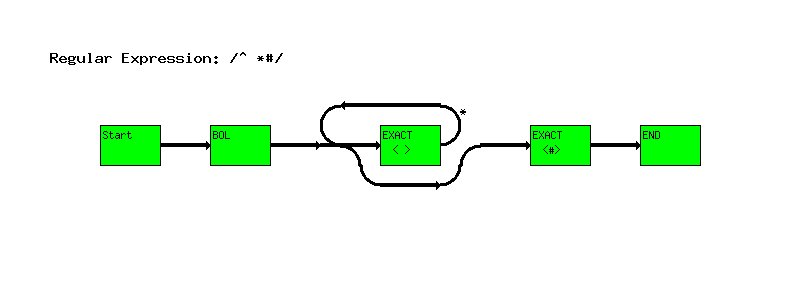
The way the state machine works it that it starts at ``Start'' and works it's way through the nodes. You'll notice that between ``BOL'' and ``EXACT < >'' there's a fork in the road.
The state machine will take the top branch if possible. So if the next character is a space, the system will take the top branch and match the ``EXACT < >'' node. If not, the bottom branch is taken and we wind up at the ``EXACT <#>'' node.
If there's no path to the ``END'', then we don't have a match.
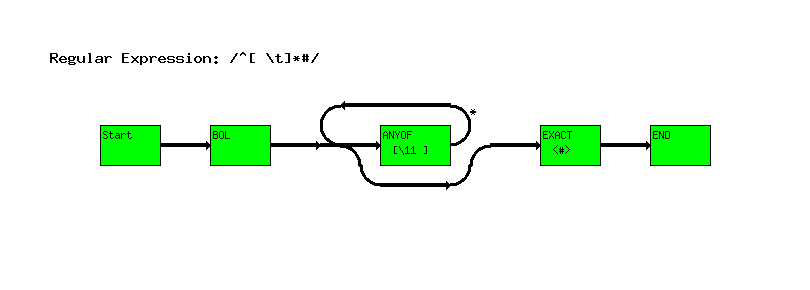
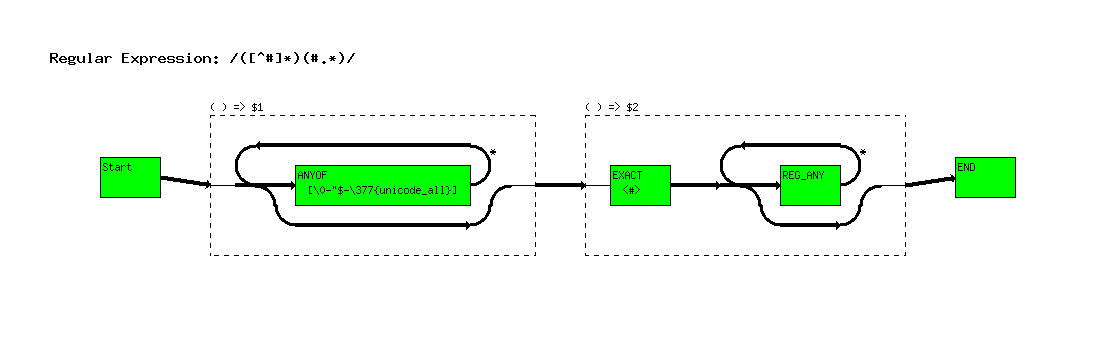
The other change is that we use the expression [^#], which matches anything except a hash mark. Perl changes this to a ``ANYOF'' clauses which matches all characters except the single one we don't want.
Note: This ANYOF node overflows the size of the box. This is a know bug.
The graphing program can show how the regular expression excution process. Let's see what happens when we run the command:
perl re_graph.pl -o tut_06_%d.png '([^#]*)(#.*)' 'text # Comment'
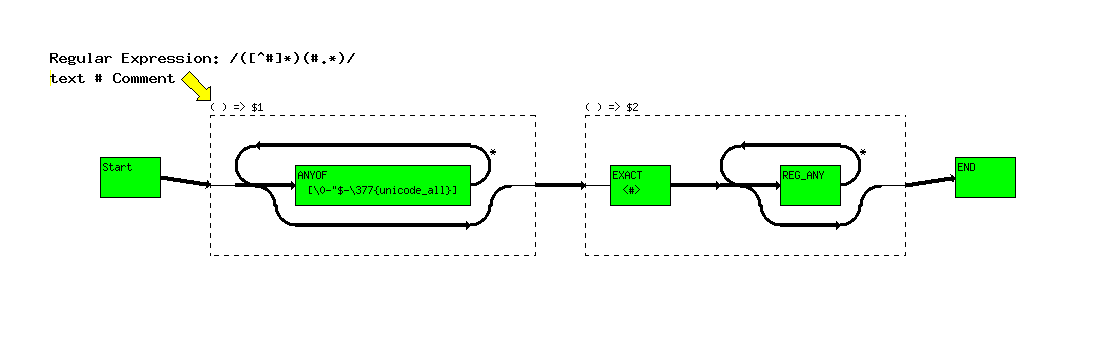
The first image show a yellow arrow pointing to the first set of (), indicating that the system is about to go into $1.
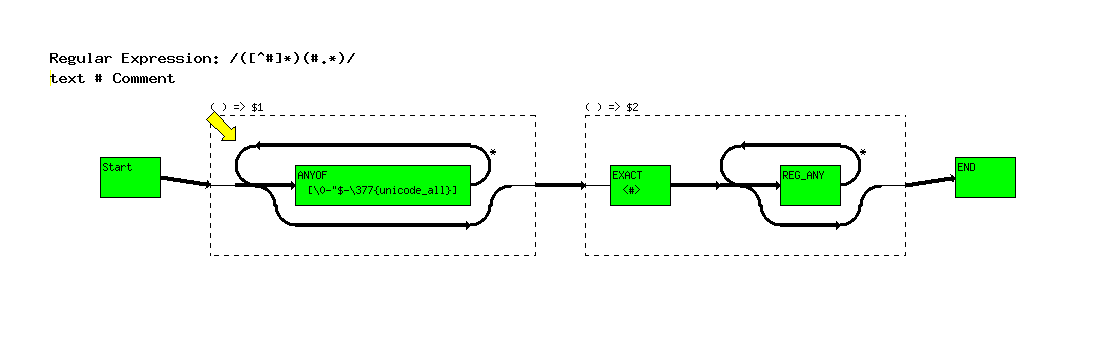
The next yellow arrow points at the ANYOF operator indicating that
the regular expression engine is about to look at the [^#] part
of the expression.
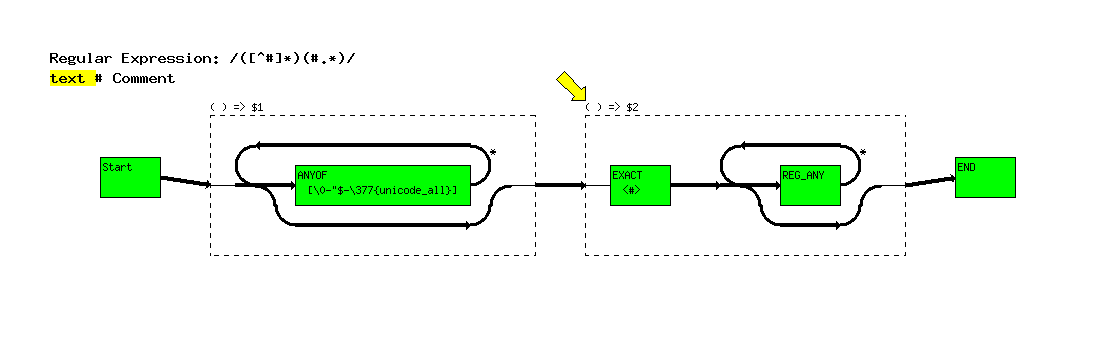
In the next screen, the yellow arrow has moved to the box
representing the second set of (). That means that the first
part of matching process is done. The string text is highlighted
yellowing, indicating that that much of the string has be matched
so far.
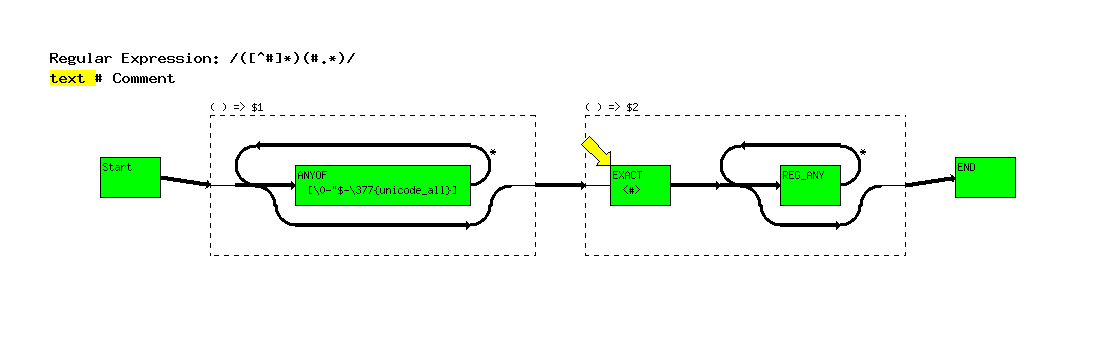
Next the yellow arrow points to the ``#'' node. The string is highlighted up to the just before the ``#''. This tells us that engine is about to match the ``#'' in the string against the ``#'' in the regular expression.
The next few images (not shown) show the engine matching the rest of the string.
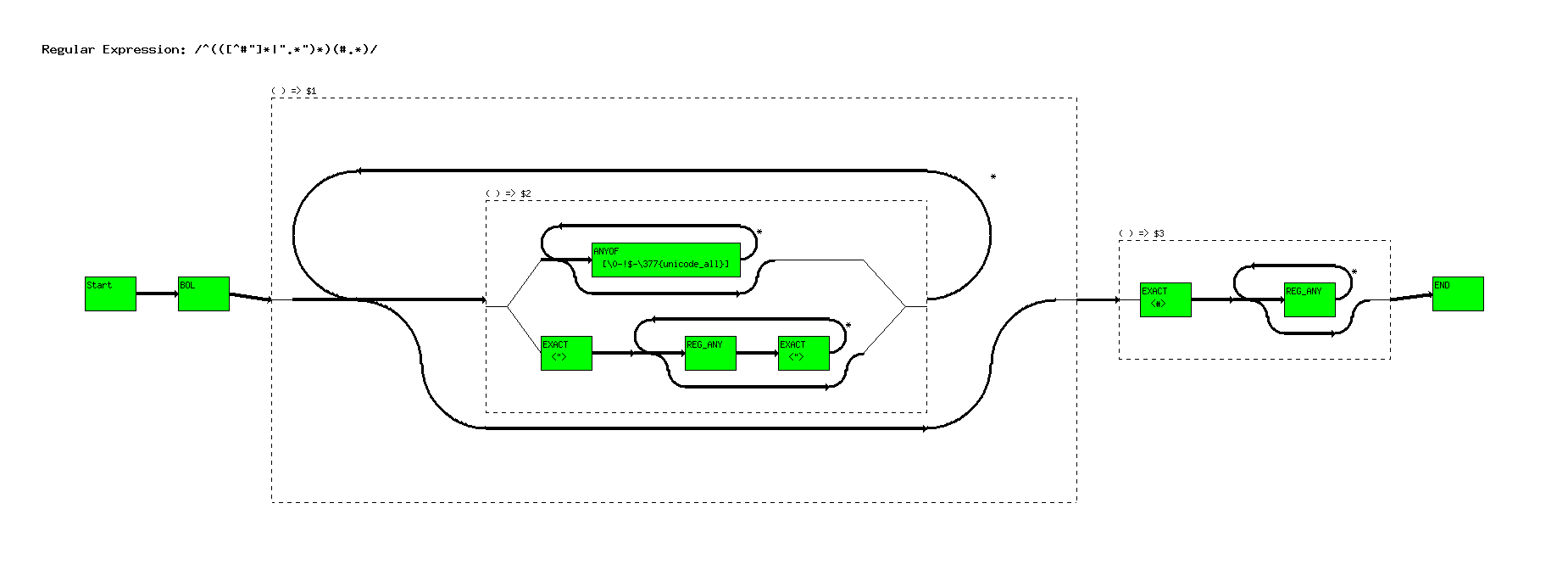
This expression adds nested grouping, and some additional stuff that we've seen before.
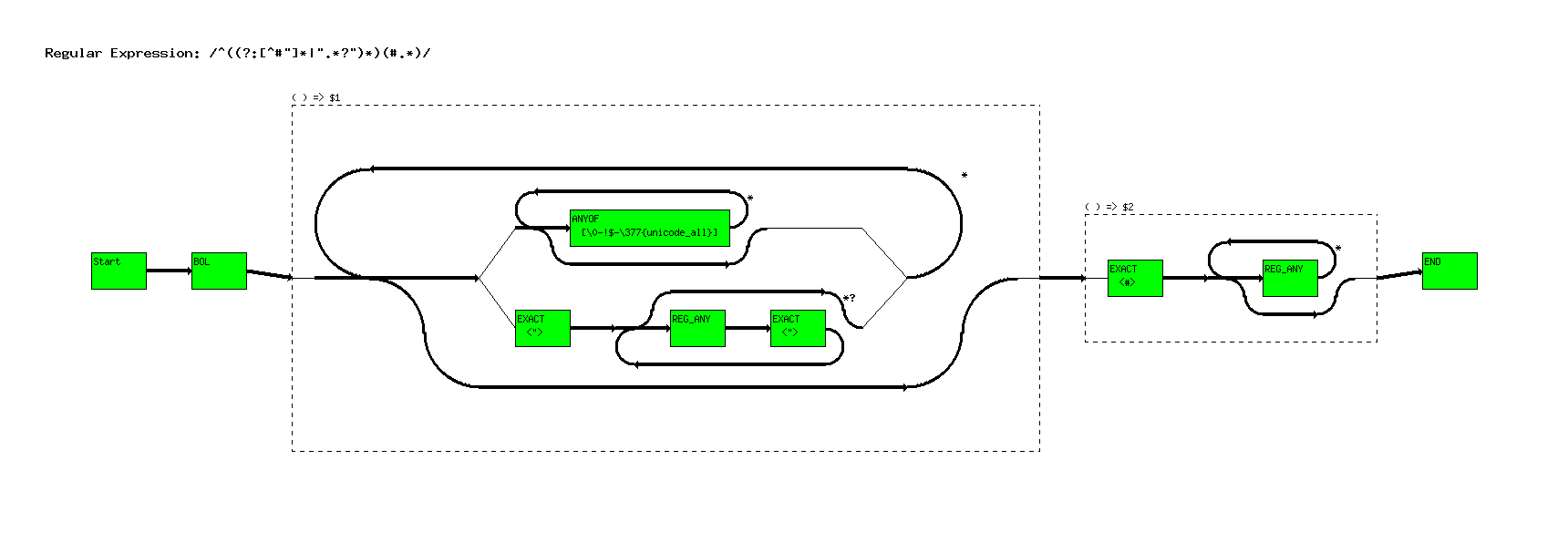
(In future versions of this graphing tool we will graph the invisible group operator. We just did figure out how to do it yet.)
Also notice the use of the ``*?'' operator. Remember when going through the nodes, when a branch is encountered, the system will try and take the top one first.
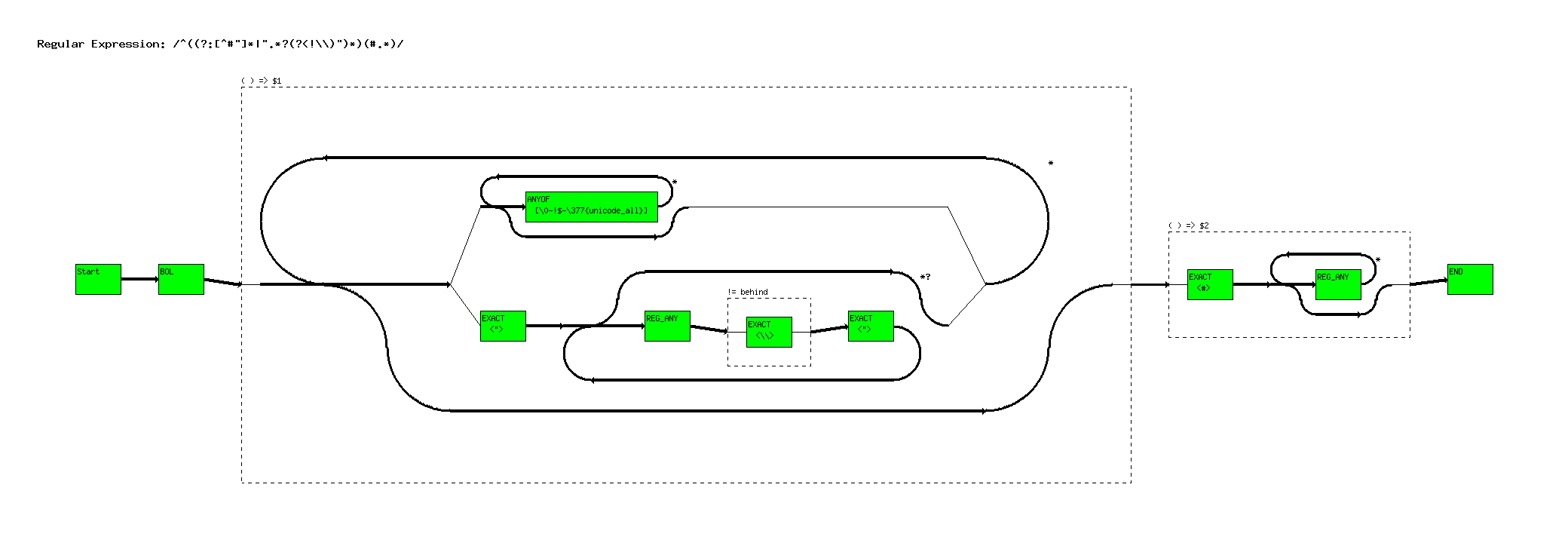
Basically the clause in question looks for a double quoted string (``xxx''), but will ignore a double quote it's escaped (``xxx\''yyy``).
This will not graph all the regular expressions. Some of the more advanced features of the engine are just not handled.
We currently ``graph'' the ``group, no $1'' (?:..) operator by displaying nothing. A box should be put around the expression.
The boxes drawn by the program are a fixed with not related to the size of the text they contain. Text can easily overflow the box.
The system is UNIX/Linux specific. This is caused by only one small section of code should anyone want to port this to a braindamaged operating system.
Better use of color can be made. Specifically all the nodes do not have to be green. Come to think of it they call don't have to be rectangles either.
Sometimes the lines connecting one section to another take some strange twists.
Licensed under the GPL. (See the end of the source file for a copy).
Steve Oualline (oualline (at) www.oualline.com)